Heute möchte ich mich mal mit dem Thema Feeder in TM1 beschäftigen. Ich habe zu Beginn meines Berater-Daseins eine ganze Weile gebraucht, bis ich Feeder in TM1 bedingungslos verstanden habe. Damit man die Logik und den Sinn von Feedern versteht, muss man sich zunächst mit Rules und dann mit dem Sparse Consolidation Algorithmus beschäftigen. Aber der Reihe nach.
Rules geben mir die Möglichkeit, die Business-Logik in meinem TM1-Datenmodell abzubilden. Damit wird das Ergebnis on-the-fly, also ohne Wartezeit für den Anwender, berechnet. Fangen wir mit einem sehr einfachen Beispiel an:
Umsatz = Menge * Preis
Wir wollen hier also keinen Umsatz planen, sondern lediglich einen Stückpreis und eine Absatzmenge. Der Umsatz soll dann automatisch errechnet werden. Die TM1-Rule für dieses Beispiel sieht fast genauso aus wie die Anforderung. Denn für die Rule gelten die folgende Regeln:
- Links vom Gleichheitszeichen steht die Menge, für die unsere Rule gelten soll. In unserem Fall also das Element Umsatz.
- Rechts vom Gleichheitszeichen steht die Rechenoperation, die für diese Logik gelten soll. Hier also Menge * Preis.
- Außerdem kann nach dem Gleichheitszeichen noch eingeschränkt werden, für welche Elementtypen diese Regel gelten soll. Also nummerische Elemente (N), String / Text-Elemente (S) oder konsolidierte Elemente (C)
- Jede Rule wird mit einem Semikolon abgeschlossen.
Wie sieht nun also unsere Rule in der TM1-Syntax aus?
[‚Umsatz‘] = N: [‚Menge‘] * [‚Preis‘];
Im Klartext: Für alle nummerischen Zellen mit dem Element „Umsatz“ gilt die Regel Umsatz = Menge * Preis.
Klar, es gibt noch deutlich komplexere Berechnungen, aber für den Anfang wollen wir uns auf etwas einfaches beschränken. Denn dieses Beispiel reicht schon, um die Feeder in TM1 bedingungslos zu verstehen.
Und wie sieht nun der Feeder aus. Und warum braucht man den überhaupt?
Tja, TM1 ist ja eine multidimensionale Datenbank. Die einzelnen Werte werden also durch die Schnittpunkte der Dimensionselemente in einem Würfel bestimmt. Ein passender Würfel für unsere Anforderung könnte aus den Dimensionen für die Jahre, die Kunden und die Produkte bestehen. Außerdem haben wir eine Measure-Dimension.
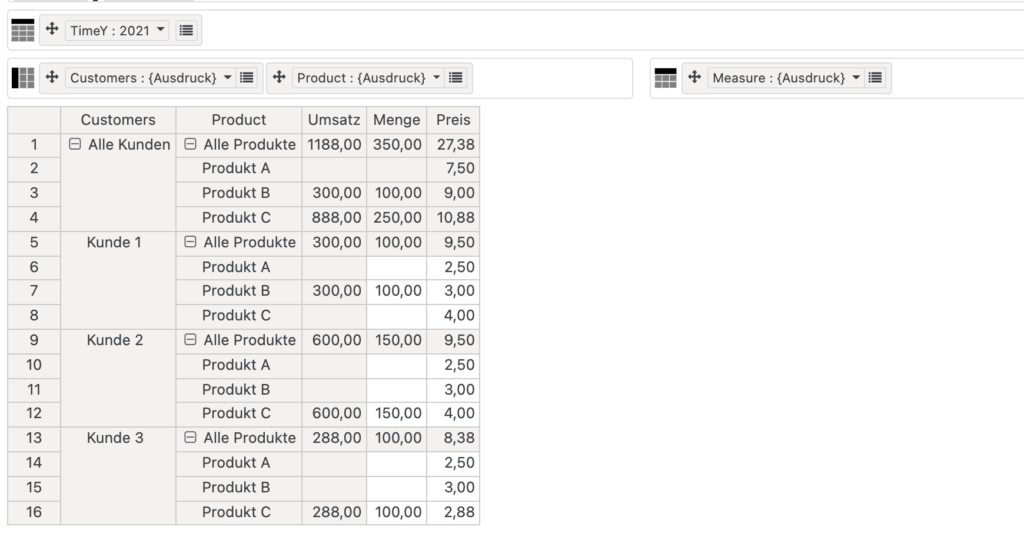
In einer relationalen Tabelle könnten die gleichen Daten so aussehen (nur bezogen auf die Menge)
| Customer | Product | Menge |
| Kunde 1 | Produkt B | 100,00 |
| Kunde 2 | Produkt C | 150,00 |
| Kunde 3 | Product C | 100,00 |
In diesem einfachen Würfel sieht man schnell das Problem einer multidimensionalen Datenbank. Denn dort sind sehr viele Zellen gar nicht belegt. Die Zellen existieren, tragen aber keine Werte. In einer relationalen Datenbank, existieren die Datensätze gar nicht erst.
Um nun die Summe der Menge aller Produkte zu berechnen, reicht es in der relationalen Datenbank die Wete 100, 150 und 100 aufzuaddieren. In der multidimensionalen Datenbank heißt die Rechnung: 0+100+0+0+0+150+0+0+100 = 350.
In großen Würfeln mit umfangreichen Dimensionen kann das natürlich zu einem massiven Problem werden.
Der Sparse Consolidation Algorithmus
In TM1 wird dieses Problem durch den Sparse Consolidation Algorithmus (SCA) behoben. Dieser sorgt übrigens auch dafür, dass wir in Berichten oder im Cube-Viewer eine Nullunterdrückung verwenden können. Im Kern sagt dieser Algorithmus aus, dass nur Zellen für die Berechnung berücksichtigt werden, die einen Wert im Arbeitsspeicher haben. In dem einfachen Beispiel von oben lautet die Rechung dann wieder 100+150+100.
Und was hat nun das ganze mit Feedern zu tun?
Gehen wir dazu zurück zu unserem Eingangsbeispiel (Umsatz = Menge * Preis). Für die Menge funktioniert die Konsolidierung wunderbar. Zellen, die im Speicher keinen Wert haben, müssen nicht berücksichtigt werden. Das sind die 0en, die man einfach weglassen kann.
Beim Umsatz ist es allerdings anders. Hier enthält die jeweilige Speicheradresse nirgendwo einen wirklichen Wert. Im Würfel steht hier nichts. Die Speicheradresse ist demzufolge leer. Denn der Umsatz wird ja aus anderen Komponenten berechnet. TM1 überspringt aber durch den SCA die Zellen ohne Werte. Das Ergebnis wäre dann falsch.
Der sonst so praktische SCA spuckt uns hier gehörig in die Suppe. Deshalb sind die IBM-Entwickler einen einfachen Weg gegangen. Sobald ein Würfel eine Rule hat, schalten sie den SCA einfach aus. Die Zellen ohne einen Wert im Speicher werden also wieder mit berücksichtigt. Das Ergebnis ist dadurch richtig. Die Berechnung aber deutlich zeitintensiver.
Skipcheck schaltet den SCA auch in regelberechneten Würfeln wieder an
In den meisten Fällen hilft es nichts: wir brauchen den SCA um performante Modelle zu bekommen. Was tun wir? Wir schalten ihn wieder ein. Und zwar mit dem Befehl „skipcheck“ ganz zu Beginn der Rule. Dadurch wird der Cube wieder schnell. Allerdings müssen die Zellen, die keinen Wert im Speicher haben, aber trotzdem in der Konsolidierung berücksichtigt werden müssen, speziell markiert werden. Sie müssen gefeedert werden.
Solange diese Markierung nicht erfolgt ist, nenne ich diese Zellen gerne Geisterzellen. Sie sind vorhanden, aber irgendwie auch nicht. Sie geistern nur im System herum und haben keinen wirklichen Nutzen.
Diese Geisterzellen müssen wir also markieren, damit sie wieder Teil der Gesamtsumme werden. Technisch ausgedrückt: Die entsprechende Speicheradresse muss mit einem Wert versehen werden. Und das erreichen wir mit einem Feeder.
Die Feeder in einer Rule-Datei werden mit dem „feeders;“-Statement eingeleitet und befinden sich immer am Ende der Rule, also nach allen Business-Logiken. Weil man sie nur braucht, wenn der SCA ausgeschaltet ist, gibt es sie nur dort, wo auch skipcheck verwendet wird.
Die Menge feedert den Umsatz, nicht der Preis. Oder?
Der Feeder für unser Menge * Preis-Beispiel sieht so aus:
[‚Menge‘] => [‚Umsatz‘];
Weil dieser Feeder keinerlei Bedingung hat, passt er perfekt zum Thema: Feeder in TM1 bedingungslos verstehen.
Erst kommt der Wert, den wir als Trigger für unsere Berechnung benutzen können. In diesem Fall können wir sagen: dort wo es eine Menge gibt, gibt es wohl auch einen Umsatz. Die Menge ist also unser Trigger. Wann immer der Wert der Zelle Menge ungleich 0 ist, soll auf jeden Fall die dazugehörige Umsatzzelle mit in die Berechnung eingehen.
Nach dem Triggert folgt ein Pfeil, und dann die Elemente, die wir feedern müssen, hier also den Umsatz. Der Feeder wird, wie auch schon die Rule, mit einem Semikolon abgeschlossen.
Wie schon gesagt sorgt der Feeder dafür, dass die Zielzelle, unsere vorherige Geisterzelle, mit einem Wert (nämlich einem Bit) im Speicher versehen wird. Die Folge: je mehr Feeder, desto mehr RAM-Verbrauch.
Um schlanke, performante und dennoch korrekte Modelle zu entwickeln, gilt also eine einfache Regel: so viel wie nötig, so wenig wie möglich. Und: je zielgenauer Dein Feeder ist, desto weniger RAM wirst Du benötigen. Feederst Du zum Beispiel „alle Produkte“ oder „alle Monate“, wird dein Feeder möglicherweise auch dort RAM verbrauchen, wo Du ihn gar nicht zwingend brauchst. Hier spricht man vom overfeedern. Das ist nicht besonders gut, aber immer noch besser als underfeedern. Denn bei zu wenig gesetzten Feedern, sind die Ergebnisse Deines Modells falsch.
Preisfrage: warum feedert man von der Menge, und nicht vom Preis?
Ein Feeder beginnt mit seiner Arbeit immer dann, wenn der Trigger von 0 auf einen anderen Wert springt. Mit diesem Wissen wird klar, warum in meinem Beispiel die Menge, und nicht der Preis ausschlaggebend für den Feeder ist.
In der Regel hat jedes Produkt einen Preis, ganz egal ob es verkauft wird oder nicht. Es ist möglich, dass bei einem Produkt oder einem Kunden die Menge gleich 0 ist, einfach weil es nicht verkauft wurde. Dass der Preis 0 ist, ist hingegen eher unwahrscheinlich.
Also: nutze ich die Menge als Trigger, wird mein Feeder weniger häufig ausgelöst. Dadurch benötige ich auch weniger Ressourcen. Was man dabei gut erkennt: damit Du Feeder klug setzen kannst, musst Du die fachliche Anforderung verstanden haben. Mit dem technischen Knowhow allein kommst Du nicht weiter.
Machen wir das Beispiel etwas weniger alltäglich: mein Business verschickt an jeden Kunden mindestens ein Produkt. Manche Kunden erhalten das Produkt kostenlos. Hier ist der Preis also 0. Andere müssen dafür etwas bezahlen. Bei allen Kunden ist die Menge aber immer größer als 0. In dem Fall wäre es tatsächlich sinnvoller, vom Preis zu feedern, weil dieser mit höherer Wahrscheinlichkeit 0 ist. Wodurch ich also weniger häufig feedern würde.
Wir halten also fest: wir feedern immer von dem Wert, der mit einer höheren Wahrscheinlichkeit 0 ist, um ressourcensparend zu feedern. Ob der Trigger nun die Menge, oder der Preis ist, ist letztlich auch eine Frage des Preises.
Verhalten bei Additionen und Subtraktionen
Wird die Business-Logik komplizierter, wird auch der Feeder komplizierter und benötigt etwas mehr Aufmerksamkeit. Setzt sich der Umsatz zum Beispiel aus „(Menge * Preis) + monatliche Pauschale“ zusammen, reicht meine Menge ggf. nicht mehr als Trigger aus. Es könnte ja sein, dass der Kunde auch bei einer 0-Menge eine Rechnung bekommt. Und die soll ja mit in den Umsatz eingehen. In diesem Fall benötige ich also zwei Feeder:
[‚Menge‘] => [‚Umsatz‘];
[‚monatliche Pauschale‘] => [‚Umsatz‘]
Bei einer Multiplikation oder einer Division ist es (fast) egal, welchen der Faktoren ich zum Feedern heranziehe; es reicht wenn ich einen der Faktoren berücksichtige. Sobald aber mehrere Komponenten auf die berechnete Zelle wirken, die auch bei einer 0 zu einem Ergebnis führen können, muss ich von mehreren Zellen aus feedern. Denn nur so kann ich sicher sein, dass die Zelle immer gefeedert ist, wenn das Ergebnis der Berechnung nicht 0 ist.
Feeder in TM1 bedingungslos? Gibt es denn auch Feeder mit Bedingung in TM1?
Bis hierher alles verstanden? Prima. Denn erst wenn du Feeder in TM1 bedingungslos verstanden hast, solltest Du den nächsten Schritt machen. Dann kannst Du Dich den bedingten Feedern in TM1 widmen. Die gibt es nämlich auch noch. Doch dazu später mehr.