Kürzlich habe ich schon etwas über bedingungslose Feeder in TM1 geschrieben. Hast Du das bedingungslos verstanden? Wenn ja, dann kannst Du hier etwas über bedingte Feeder in TM1 lesen. Andernfalls gehe lieber nochmal zurück.
Wie Du weißt sind Feeder notwendig, um korrekte Konsolidierungen in TM1 zu erhalten. Zumindest dann, wenn Du skipcheck verwendest. Der Preis für Feeder ist aber auch nicht zu unterschätzen. Ohne Skipcheck und Feeder hätte ich eine desaströs schlechte Performance. Mit Skipcheck und Feedern wird das natürlich besser, aber die Performance hat im Vergleich zu Berechnungen über den Turbointegrator-Prozess oder über die Struktur immer noch das Nachsehen. Ein höherer RAM-Verbrauch, eine in der Regel längere Startup-Zeit sowie längere Cube-Load-Zeiten sind mögliche Effekte.
Die Nachteile von Feedern sind also nicht zu unterschätzen. Umso wichtiger ist diese Grundregel: so viele Feeder wie nötig, so wenig wie möglich.
Eine Möglichkeit, weniger häufig zu feedern, sind bedingte Feeder. Diese Feeder treffen die Zielzelle nur dann, wenn eine bestimmte Bedingung erfüllt ist. Und damit weniger oft.
Das Menge-Preis-Beispiel
Gehen wir zurück auf unser Beispiel vom ersten Feeder-Artikel. Die Anforderung war recht einfach: der Umsatz ist die Menge, multipliziert mit dem Preis.
Nun könnte die Anforderung auch lauten: bei Produkten der Produktgruppe A wird der Umsatz berechnet. Bei Produkten aus anderen Gruppen, wird der Umsatz manuell geplant. Die Zelle soll hier für die Planung offen sein. In diesem Screenshot zeige ich schon mal, wie das Ergebnis aussehen soll.
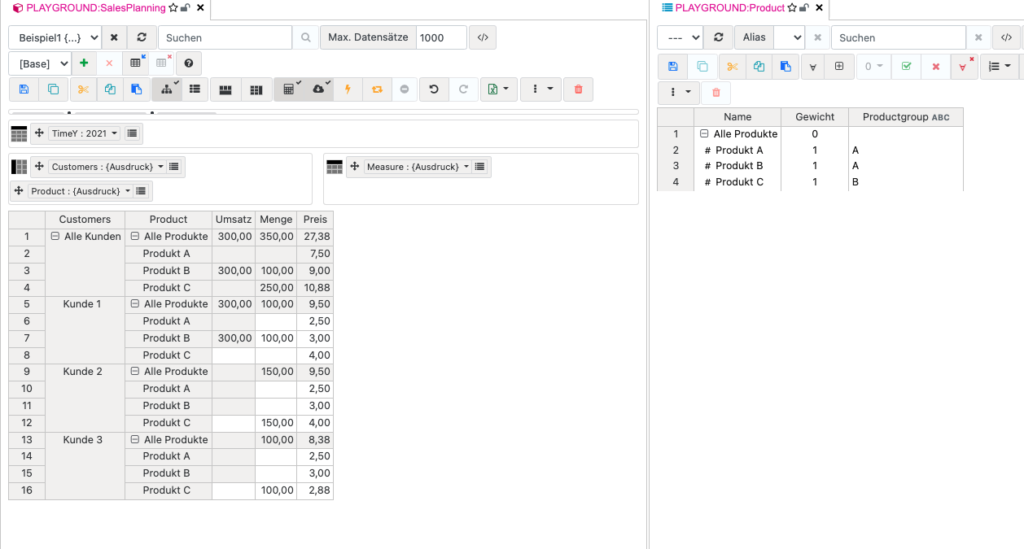
Wie Du siehst, haben meine Produkte A und B den Attributswert A für die Produktgruppe. Nur für diese Produkte soll der Umsatz also errechnet werden.
Das erreichen wir mit der folgenden Rule:

Hier wird der Umsatz also nur aus Menge und Preis errechnet, wenn die Produktgruppe A entspricht. In allen anderen Fällen gilt ein STET; die Rule wird also übersprungen und die Zellen sind frei für eine Eingabe.
Wie Du siehst, habe ich den Feeder hier noch nicht geändert. Grundsätzlich wäre es jetzt aber ausreichend, nur die Zellen zu feeden, die auch wirklich berechnet werden. Also nur den Umsatz für die Produktgruppe A.
Um das zu erreichen, gibt es mehrere Möglichkeiten. In meinem einfachen Datenmodell gehören die Produkte A und B zur Produktgruppe A. Hier könnte man also schreiben:
[{‚Produkt A‘, ‚Produkt B‘}, ‚Menge‘] => [‚Umsatz‘];
Soweit so gut. Wenn man aber unzählige Elemente hat, für die eine Bedingung erfüllt ist, wird das problematisch. Und hier kommt der bedingte Feeder in TM1 ins Spiel.
Die Syntax für den bedingten Feeder
Damit wir den bedingten Feeder verwenden können, müssen wir den Feeder auf die DB-Syntax umstellen. Wir nutzen also nicht mehr die Schreibweise mit den eckigen Klammern, sondern sprechen die zu feedernden Zellen über eine DB-Funktion an:
[‚Menge‘] => DB(‚SalesPlanning‘, !TimeY, !Customers, !Product, ‚Umsatz‘);
Die Menge feedert also in den SalesPlanningCube, auf die entsprechenden Koordinaten von TimeY, Customers und Product und auf das Element Umsatz.
Die Bedingung implementieren wir im nächsten Schritt. Links vom Pfeil können wir nur eine Liste von Elementen angeben. Die Bedingung müssen wir rechts vom Pfeil implementieren. Wenn ich nun meinen Feeder nicht aktivieren möchte, lasse ich ihn eben einfach ins Leere feuern. Und das geht so:

Wie Du siehst, habe ich die anderen Feeder in den Zeilen 11 und 12 auskommentiert. In den Zeilen 14 bis 18 siehst Du jetzt den Feeder mit einer Bedingung.
Die Syntax mit der DB-Funktion ist geblieben. Meine Bedingung habe ich in das erste Argument der DB-Funktion gebaut. Anstatt hier einfach den Würfelnamen anzugeben, knüpfe ich den Würfelnamen an eine IF-Funktion. Nur wenn die Produktgruppe gleich A ist, lautet der Würfelname SalesPlanning. In allen anderen Fällen ist es einfach ein leerer String. Einen Würfel ohne Namen gibt es nicht. Deswegen zeigt mein Feeder in dem Fall ins Leere. Nach meinem IF-Statement kommt der Rest der DB-Funktion, so wie ich es schon zuvor implementiert hatte.
Denk dran wann ein Feeder triggerd
In dem Zuge möchte ich aber noch auf einen Stolperstein hinweisen, der häufig auftritt, wenn man bedingte Feeder in TM1 verwendet. Erinnere Dich an den letzten Artikel zu dem Thema. Der Feeder triggerd dann, wenn die Triggerzelle von 0 auf einen anderen Wert wechselt. Hier also immer dann, wenn sich die Menge verändert. Ändert sich hingegen die Bedingung, zum Beispiel weil ein weiteres Produkt in die Produktgruppe A aufgenommen wird, ändert das nichts an der Menge. Der Feeder löst also gar nicht aus.
Bei Feederketten solltest Du Dir in diesem Zusammenhang auch den Parameter ForceReevaluationOfFeedersForFedCellsOnDataChange der tm1s.cfg anschauen. Früher hatte man den einfach ReevaluateConditionalFeeders genannt.
Wenn Du sichergehen willst, dass die bedingten Feeder auch wirklich ausgelöst haben, solltest Du auf jeden Fall die Funktion CubeProcessFeeders in einem Turbointegrator-Prozess verwenden.
Einfache Regel beachten: vermeide Fehler!
Verwendest Du bedingte Feeder in TM1, läufst Du Gefahr, Fehler in den Feeder einzubauen, die keine Fehlermeldung zurückgeben. Das folgende Feeder-Statement ist syntaktisch korrekt:
[‚Menge‘] => DB( IF(AttrS(‚Product‘, !Product, ‚Productgroup‘)@=’A‘, ‚Sales_Planning‘, “), !TimeY, !Customers, !Product, ‚Umsatz‘);
Leider feedert aber diese Zeile in meinem Modell niemals, da mein Würfel nun mal SalesPlanning und nicht Sales_Planning heißt. Eine Fehlermeldung bekommt man aber leider nicht.
Dabei muss man auch daran denken: ein Feeder bleibt im RAM erhalten, bis der Cube entladen oder das Modell neu gestartet wird. Wenn Deine Zielzelle also gefeedert ist, ist es trotzdem möglich, dass der Feeder falsch ist und nach dem nächsten Neustart nicht mehr funktioniert.
Immer CubeUnload für bedingte Feeder in TM1
Wenn ich komplexere Feeder schreibe oder mir nicht wirklich sehr sicher bin, dass das Ganze auch funktioniert, entlade ich daher immer erst den Würfel, bevor ich meine Tests mache. Nur so kann ich sicher sein, dass meine Entwicklung auch den nächsten Neustart überlebt.
Warum der bedingte Feeder nicht immer die beste Idee ist
Auf den Stolperstein, dass ein Feeder nur gerechnet wird, wenn die Triggerzelle sich ändert, habe ich Dich schon hingewiesen. Unabhängig von jeder Diskussion über Performance, Serverload-Zeit oder Ressourcen-Verbrauch: es geht nichts über ein korrekt rechnendes Datenmodell.
Außerdem muss ich nicht nur den RAM-Verbrauch in meinem Modell berücksichtigen, sondern auch die Performance in Summe. Die Zeit, die dabei flöten geht, wenn TM1 die Bedingung meines Feeders berechnet, muss auch beachtet werden.
Der bedingte Feeder in TM1 kommt also mit nicht nur einem Nachteil. Ich behaupte: meistens gibt es eine bessere Möglichkeit, als einen bedingten Feeder zu verwenden.