Kennst du das auch? Große komplexe Dimensionen in IBM TM1, die eine lange Liste unterschiedlicher Elemente beinhalten. Und obwohl diese durch entsprechende C-Elemente untergliedert sind, ergeben sich in Reports unübersichtliche DropDown Listen.
Nehmen wir bspw. eine Produktdimension, in der die einzelnen Produkte (N-Elemente) nach Produktgruppen (C-Elemente) untergliedert sind. Diese Dimension enthält mehrere tausend Elemente. Innerhalb eines Reports in einer DropDown Liste das richtige Produkt zu finden, kann so eine nie enden wollende Aufgabe darstellen.
Wir haben die Lösung für dich: Kaskadierende Selektion. Was das ist und welche Ansätze es hierfür gibt, findest du in diesem Blogbeitrag „Kaskadierende Selektion: drei Varianten!“.
Was ist eigentlich eine kaskadierende Selektion?
Bei einer kaskadierenden Selektion handelt es sich um eine Reihe abhängiger DropDown Listen. In unserem Beispiel enthält die erste Liste die Produktgruppen. Je nachdem was du hier auswählst, z.B. Produktgruppe 1, verändern sich die Elemente die in der zweiten DropDown Liste angezeigt werden, hier: alle Elemente der Produktgruppe 1. So verringert sich die Anzahl der Objekte in der Liste und du kannst schneller, einfacher und zielgerichteter mit den Reports arbeiten.
Aber wie können kaskadierende Selektionen in einen Report eingebaut werden? Wir zeigen dir drei Varianten.
Variante 1: Kaskadierende Selektion mit Subsets
In der ersten Variante werden fixe Subsets angelegt, die den gleichen Namen tragen, wie die zugehörigen C-Elemente, die in der ersten DropDown Liste zu finden sind, in unserem Beispiel je Produktgruppen. Zu jeder Produktgruppe gibt es ein passendes Subset in dem sich alle zugehörigen Produkte finden und das den gleichen Namen wie die Produktgruppe selbst trägt.
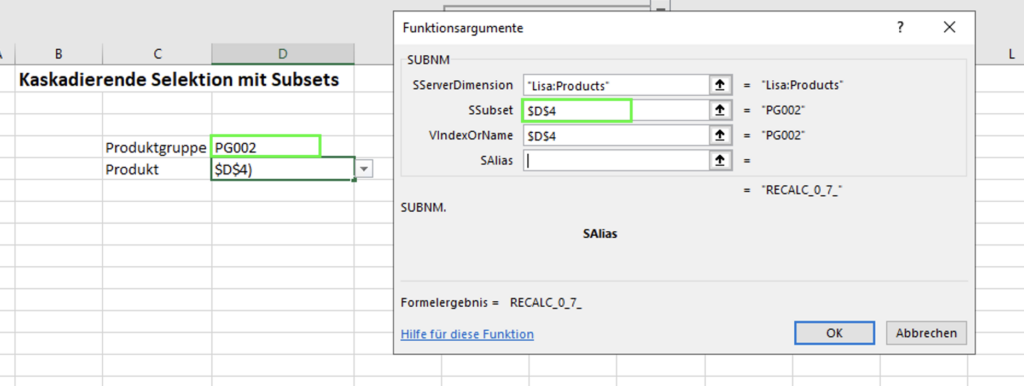
Die SUBNM Formel im Auswahlfeld der Produkte wird dann auf die Zelle der Produktgruppe als Name des anzuzeigenden Subsets verlinkt. So kann eine kaskadierende Selektion stattfinden, bei der durch die Auswahl der Produktgruppe im ersten Schritt die Liste der Produkte eingeschränkt wird.
Auch wenn diese Variante leicht umzusetzen ist, erfordert sie viel Aufwand im Hintergrund. Durch die starren Subsets, müssen bei Änderung und Erweiterung der Elemente, in unserem Beispiel neue Produktgruppen oder Produkte, die Subsets immer entsprechend nachgepflegt werden.
Um dieses Nachpflegen und Arbeiten im Hintergrund zu vermeiden kann die zweite Variante angewendet werden.
Variante 2: Kaskadierende Selektion mit MDX
In Variante 2 werden mit Hilfe eines MDX und eines zusätzlichen Cubes dynamische abhängige Auswahllisten erzeugt. Im ersten Auswahlfeld wird mit einer klassischen SUBNM Formel gearbeitet. In unserem Beispiel wieder die Produktgruppe. Die Auswahl dieser Gruppe wird dann per DBSS Formel userabhängig in einen separaten Cube geschrieben. Dieser trägt hier den Namen „App“.
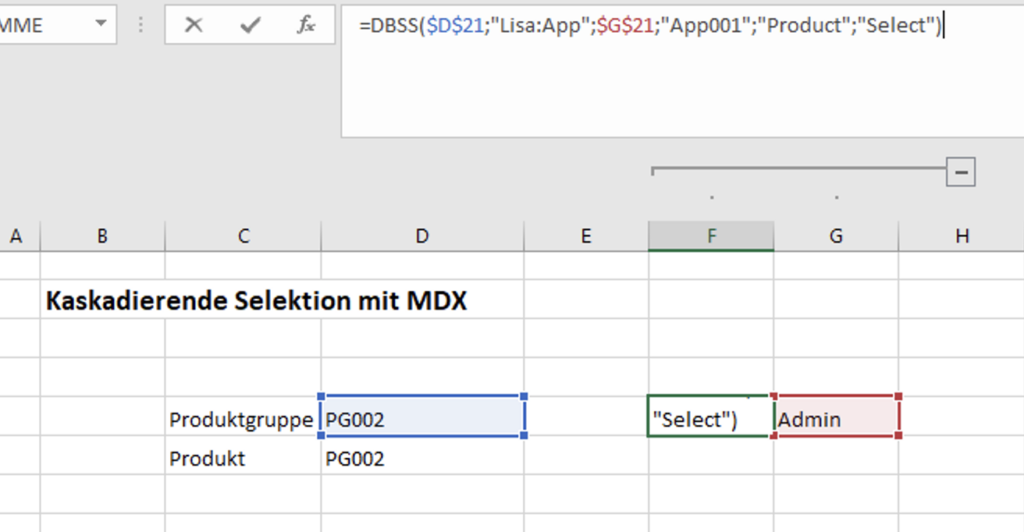
Das Subset hinter der DropDown Liste der Produkte greift auf den App Cube zu und wird so dynamisch gestaltet.
In unserem Beispiel baut sich das MDX wie folgt auf:
descendants({StrToMember(„[Products].[„+[App].(StrToMember(„[}Clients].[„+Username+“]“),[App].[App001],[AppParameter].[Product],[AppMeasure].[Select])+“]“)})
Dieses MDX ist in unserer Product Dimension als dynamisches Subset (MyProducts) gespeichert. Bei der Auswahl der Produkte wird auf dieses Subset zugegriffen.
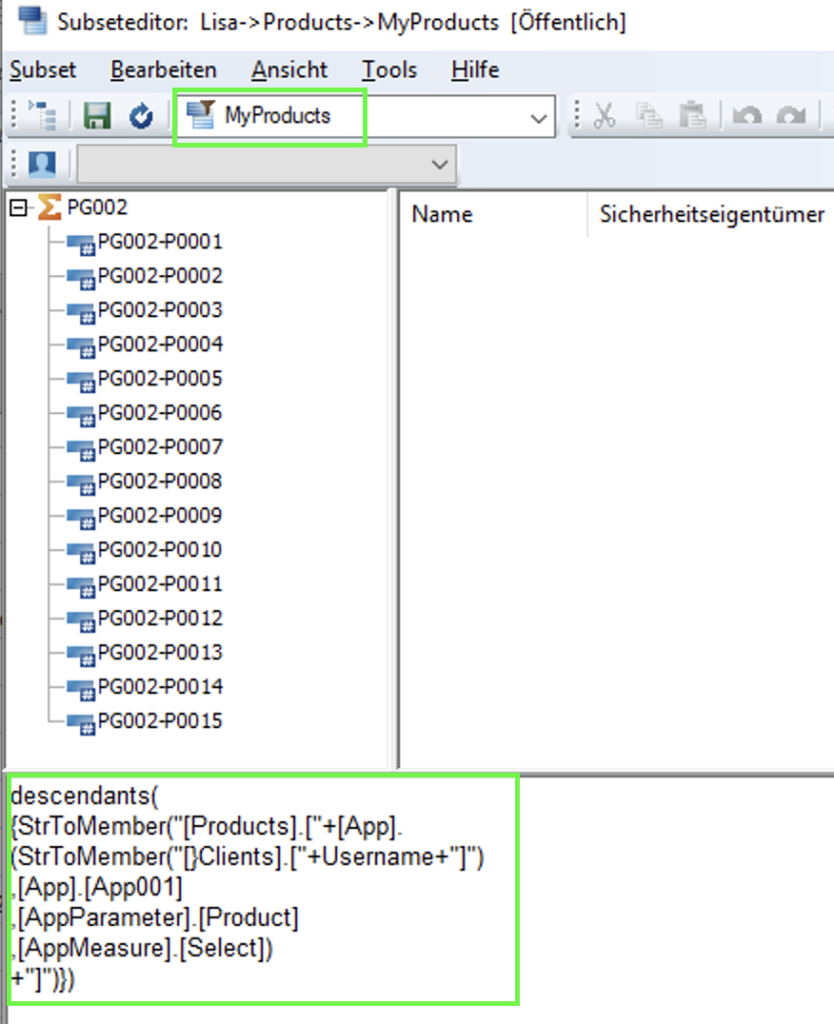
Durch die dynamische Auswahl, muss bei der Erstellung neuer Produkte oder Produktgruppen keine nachträgliche Anpassung am Subset vorgenommen werden. Allerdings muss immer mit einem separaten Cube gearbeitet werden.
Willst du einen separaten Cube vermeiden, kannst du unsere dritte Variante anwenden.
Variante 3: Kaskadierende Selektion mit TM1ELLIST
In Variante 3 wird mit Hilfe der TM1ELLIST Formel (nur in PAfE, nicht im TM1Web!) und einem dynamischen abhängigen MDX eine entsprechende kaskadierende Selektion erzeugt.
Genau wie bei den vorherigen Varianten bildet das erste DropDown Feld eine klassische SUBNM Formel, hier für die Auswahl der Produktgruppen. Diese Auswahl ist in ein MDX verlinkt, was die Grundlage der TM1ELLIST Formel bildet.
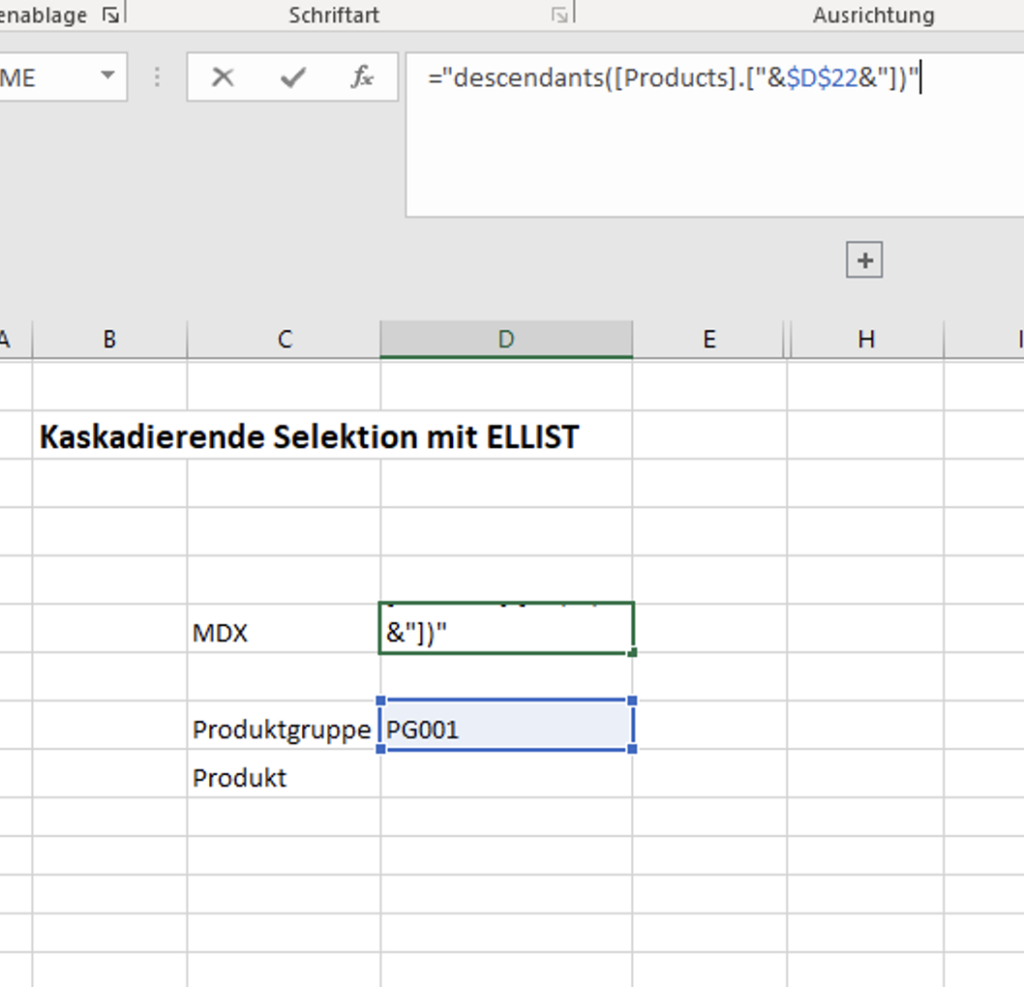
TM1ELLIST greift auf das MDX zu und erstellt eine dynamische Liste, je nach Auswahl der Produktgruppe. Im Auswahlfeld der Produkte wird dann die Spalte der TM1ELLIST Formel verlinkt. Wichtig ist an dieser Stelle die Formel in einer separaten Spalte zu verwenden, in der keine anderen Werte zu finden sind (diese kann dann ausgeblendet werden und ist so nicht mehr im Report sichtbar).

Durch den dynamischen Aufbau, muss man hier, genau wie bei Variante 2 das MDX nicht nachpflegen, sobald Produkte oder Produktgruppen geändert oder hinzugefügt werden. Allerdings benötigt die Formel eine eigene Spalte im Report.
Unser Fazit
Die EINE Lösung gibt es nicht! Du hast in unserem Blogbeitrag drei unterschiedliche Varianten kennengelernt, um einen kaskadierende Selektion umzusetzen. Jede mit ihren ganz eigenen Vor- und Nachteilen. Welche Variante am besten passt, ist am Ende situationsabhängig und sicher auch von den persönlichen Vorlieben beeinflusst.
Welche Variante hat dir am besten gefallen? Oder kennst du noch eine ganz andere Möglichkeit kaskadierende Selektion umzusetzen?
Falls du mehr dazu wissen möchtest, schreibe uns gerne an info@squared-force.de oder nutze unser Kontaktformular.
Übrigens hier geht es zu unserem Newsletter mit regelmäßigen Tipps und Tricks.